2026年4月,AI助手会议深剖:从概念到面试通关



文章标题:2026年4月,AI助手会议深剖:从概念到面试通关发布时间:北京时间2026年4月9日
目标读者:技术入门/进阶学习者、在校学生、面试备考者、相关技术栈开发工程师
文章定位:技术科普 + 原理讲解 + 代码示例 + 面试要点,兼顾易懂性与实用性
写作风格:条理清晰、由浅入深、语言通俗、重点突出
核心目标:让读者理解概念、理清逻辑、看懂示例、记住考点,建立完整知识链路

二、整体结构与正文
开篇引入
2026年被公认为“AI智能体元年”,AI正从单一的聊天机器人转变为具备自主规划、工具调用与记忆能力的智能体-4。无论是在日常生活中的智能语音助手,还是企业级应用的数字员工,AI助手(AI Assistant)技术正以前所未有的速度渗透到我们工作和学习的方方面面。
很多学习者在接触这项技术时常遇到这样的困境:会用现成的工具,却讲不清底层原理;概念一堆——Agent、LLM、RAG、MCP——傻傻分不清;面试被问到“什么是Agent”时,只答得出一句“就是能调用工具的AI”,然后就卡壳了。
本文将从最基础的痛点出发,带你厘清AI助手技术的核心概念与底层逻辑,配合可运行的代码示例和高频面试题解析,帮你建立从“知道”到“懂得”的完整知识链路。
痛点切入:为什么需要AI助手——从传统RPA到大模型原生的范式跃迁
传统上,要实现流程自动化,企业依赖的是RPA(机器人流程自动化)——通过录制脚本、定位XPath、编写硬编码API来模拟人工操作。来看一段简化的传统RPA脚本示例:
传统RPA脚本(基于规则的自动化) import pyautogui import time def legacy_rpa_task(): 依赖固定坐标和界面元素定位 pyautogui.click(x=350, y=450) 点击“查询”按钮(固定坐标) time.sleep(2) pyautogui.write("2026-04-09") 输入日期(固定格式) pyautogui.press('enter') 一旦界面升级或按钮位置变动,脚本立即失效 return "任务执行完毕"
传统RPA的痛点:
高耦合、低鲁棒:依赖固定坐标和UI元素定位,任何界面升级都会导致脚本大面积失效-11。
维护成本高:每一次业务规则变更都需要人工重写脚本,IT运维团队陷入无休止的修补工作中。
缺乏泛化能力:无法理解自然语言指令,无法处理非结构化信息,只能执行预设的“流水线”操作。
无法自主决策:遇到异常情况无法自适应调整,只能报错或退出。
正是为了破解这些痛点,大模型原生智能体(LLM-native Agent)应运而生。2026年,从“被动执行”向“自主感知与决策”的范式转移已成为不可逆的技术趋势-11。AI助手不再只是一个“听话的工具”,而是一个具备“大脑+手脚+记忆”的智能系统。
核心概念讲解:什么是AI Agent?
定义:AI Agent(AI智能体) 是指一种能够自主感知环境、理解用户意图、进行逻辑推理与任务规划、调用工具完成目标,并具备自我迭代能力的AI系统-50。
为了更好地理解,我们可以拆解这个定义中的几个关键词:
自主感知:Agent能够“看到”和“听到”环境信息,包括文本、图像、音频、传感器数据等。这是Agent的“眼睛与耳朵”-7。
推理与规划:面对复杂任务,Agent不是一次性回答,而是像人一样思考——“我需要先做什么,再做什么”,将大目标拆解为可执行的子步骤。
工具调用:Agent不仅能“说”,还能“做”——调用API、执行代码、操作数据库、发送邮件等,这是Agent的“手脚”-4。
记忆与迭代:Agent能记住之前的对话内容和操作经验,并根据执行结果反馈不断调整策略。
生活化类比:如果把LLM(大语言模型)比作一个知识渊博但只会纸上谈兵的学者——你问他“如何做一顿法餐”,他能洋洋洒洒写出一篇万字论文;而AI Agent则像一个具备实战经验的厨师——你告诉它“今晚做一顿法餐”,它会自己规划菜单、去超市买菜、按步骤烹饪、根据口味调整,最后把做好的菜端到你面前。LLM是“大脑”,Agent是“大脑+手脚+记忆+工具”-62。
关联概念讲解:LLM(大语言模型)
定义:LLM(Large Language Model,大语言模型) 是基于Transformer架构,通过海量文本数据进行预训练,拥有数十亿乃至万亿参数的人工智能模型-。
LLM的核心能力是学习人类语言的语法、语义、知识与逻辑,从而实现理解、生成、推理、对话等能力。但它有一个天生的局限:它只能“回答问题”,不能“完成任务”。你问它“明天的天气如何”,它能告诉你查询天气的方法,但它自己不会去调用天气API。
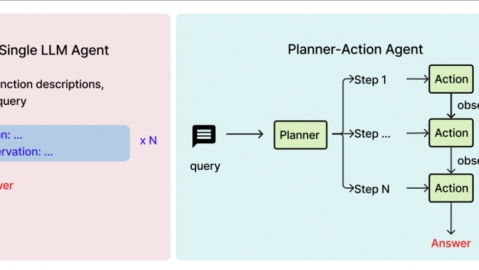
LLM与Agent的关系:LLM是Agent的“核心推理单元”,扮演整个系统的“大脑”角色-49。Agent = LLM(大脑)+ 规划(Planning)+ 记忆(Memory)+ 工具(Tools)+ 反馈循环(Feedback Loop)-61。简单说:LLM负责“想”,Agent负责“想+做”。
一句话概括:LLM是认知能力,Agent是完整的行动能力。
概念关系与区别总结
| 维度 | LLM | Agent |
|---|---|---|
| 核心定位 | 推理引擎/大脑 | 完整智能系统 |
| 交互模式 | 被动问答 | 主动目标驱动 |
| 有无规划能力 | ❌ 无 | ✅ 有(任务分解) |
| 有无工具调用 | ❌ 无(需外部编排) | ✅ 有(原生集成) |
| 有无记忆系统 | 仅上下文窗口 | 分层记忆(短期+长期+RAG) |
| 有无反馈迭代 | ❌ 无 | ✅ 有(自我修正) |
一句话速记:LLM是单次问答的“学霸”,Agent是多步闭环的“实干家”。
代码/流程示例:一个极简的Agent实现
下面用Python演示一个最简化的Agent工作流程。为突出重点,我们模拟一个“天气查询Agent”:
极简Agent示例:天气查询助手(模拟LLM推理+工具调用) import json from typing import Dict, Any class SimpleAgent: def __init__(self, llm_model): self.llm = llm_model LLM作为“大脑” self.memory = [] 记忆存储 self.tools = {} 可用工具注册表 def register_tool(self, name: str, func, description: str): """注册工具:Agent的“手脚”""" self.tools[name] = {"func": func, "desc": description} def think_and_act(self, user_query: str) -> str: Step 1: LLM进行意图识别和任务规划 plan = self.llm.infer(f"用户需求:{user_query},可用工具:{list(self.tools.keys())},请输出JSON格式的执行计划") Step 2: 按照计划执行工具调用 for action in plan["steps"]: tool_name = action["tool"] params = action["params"] if tool_name in self.tools: result = self.tools[tool_name]["func"](params) self.memory.append({"action": tool_name, "result": result}) 记忆存储 Step 3: 汇总结果生成最终回复 final_answer = self.llm.infer(f"基于执行结果{self.memory},生成用户友好的回复") return final_answer 模拟天气查询工具 def get_weather(city: str, date: str) -> Dict[str, Any]: 实际场景中这里调用真实天气API return {"city": city, "date": date, "temperature": "22°C", "condition": "晴"} 运行示例 agent = SimpleAgent(llm_model=mock_llm) mock_llm为模拟的LLM推理函数 agent.register_tool("get_weather", get_weather, "查询指定城市指定日期的天气") response = agent.think_and_act("帮我查一下北京2026年4月9日的天气") print(response)
关键执行流程解释:
感知与规划:Agent接收用户自然语言输入,LLM将其解析为结构化任务。
工具调用:Agent识别出需要调用“get_weather”工具,自动填入参数(city=北京,date=2026-04-09)。
记忆存储:将执行结果存入memory,供后续步骤使用。
总结输出:LLM将工具返回的原始数据转化为自然语言回复。
底层原理/技术支撑
AI助手能够实现上述能力,底层依赖几个关键技术模块:
推理与规划(Planning) :基于ReAct(Reasoning + Acting)框架或CoT(Chain-of-Thought,思维链)提示工程,让LLM在每一步进行“思考→行动→观察→再思考”的循环迭代-43。
记忆系统(Memory) :包含短期上下文记忆(工作记忆)、长期知识库(通过RAG向量检索实现)和经验库(历史交互记录),形成分层记忆架构-50-62。
工具调用(Tool Use/Function Calling) :通过LLM的Function Calling能力,让模型理解工具接口定义并生成正确的调用参数。MCP(Model Context Protocol,模型上下文协议)等标准化协议进一步规范了模型与外部工具的交互方式-54。
反馈与优化(Feedback Loop) :Agent根据行动结果进行自我校验和策略调整,形成完整的执行闭环-50。
这些底层技术将在后续进阶内容中深入展开,本文仅做定位与铺垫。
高频面试题与参考答案
说明:以下题目基于2026年真实大厂AI Agent岗位面试复盘整理-41-49。
Q1:请解释什么是AI Agent?它与普通的LLM调用有什么区别?
✅ 参考答案(简洁版,适合快速背诵):
AI Agent(AI智能体)是一种能够自主感知环境、理解意图、推理规划、调用工具、记忆迭代并完成复杂任务的智能系统。
与普通LLM调用的本质区别有三:
主动性:LLM是被动问答,Agent是目标驱动、自主行动。
闭环性:LLM是一次性输出,Agent包含“规划→执行→观察→反思”的完整闭环。
能力边界:LLM只有“大脑”,Agent还有“手脚+记忆+工具”。
踩分点:明确点出Agent = LLM + Planning + Memory + Tools的组合体公式,并用“被动vs主动”来对比区分-43。
Q2:Agent通常由哪些核心组件构成?各组件的作用是什么?
✅ 参考答案:
工业界最通用的Agent架构包含四大核心模块:
LLM(大脑) :负责意图理解、逻辑推理、决策生成,是整个系统的中枢。
规划模块(Planning) :将复杂任务拆解为可执行的子步骤,常用ReAct框架实现“思考→行动→观察”循环。
记忆模块(Memory) :包含短期上下文记忆、长期知识库(RAG)、经验库,解决“遗忘”问题。
工具调用模块(Tools) :通过Function Calling调用API、数据库、代码解释器等外部能力,实现“动手”操作。
踩分点:按“大脑→规划→记忆→工具”四个维度展开,每个模块点到其核心职责-50-43。
Q3:RAG是什么?它在Agent系统中扮演什么角色?
✅ 参考答案:
RAG(Retrieval-Augmented Generation,检索增强生成)是一种让大模型在生成答案前先从外部知识库检索相关信息的技术,旨在解决LLM知识过时和“幻觉”问题-54。
在Agent系统中,RAG是记忆模块的核心实现方式之一,负责为Agent提供长期知识检索能力。当Agent需要回答超出其训练数据范围的问题时,会先通过RAG从向量数据库中召回相关文档片段,再基于这些片段生成答案。
一句话概括:RAG让Agent有了“翻资料查档案”的能力。
踩分点:解释RAG全称+核心作用(解决幻觉/知识过时),明确其在Agent记忆模块中的定位,避免与Agent本身混淆-49-。
Q4:Agent开发中常见的失败场景有哪些?如何解决?
✅ 参考答案(面试官高频追问,来自真实面经):
三大常见失败场景及解决方案:
工具调用失败:LLM生成的参数格式不正确。解决:加参数校验层,不合法则让LLM重生成;关键操作加人工兜底(Human-in-the-loop)。
上下文溢出/记忆丢失:多轮对话后上下文超长,Agent忘记原始目标。解决:做上下文压缩、定期summarize、采用滑动窗口控制长度。
目标漂移:Agent在长链路执行中偏离原始任务。解决:每一步做目标对齐,定期反思总结,必要时重新规划。
踩分点:每类问题都要给出具体对策,体现工程思维,而非只说“会出现问题”-41。
Q5:请对比LangGraph和LangChain两个主流Agent框架。
✅ 参考答案:
LangChain:组件化程度高、生态丰富,适合快速原型搭建,但在复杂任务中的延迟和Token消耗相对较高。
LangGraph:基于状态机架构,提供精细的流程控制,在复杂有状态工作流中表现最优,延迟最低,适合生产级系统-31-36。
选择建议:简单场景用LangChain快速验证,复杂多步任务用LangGraph保证可控性。
踩分点:抓住“LangChain快但重,LangGraph稳且可控”的核心对比,展现对框架设计取舍的理解-36。
结尾总结
核心知识点回顾:
LLM vs Agent:LLM是被动问答的“大脑”,Agent是“大脑+手脚+记忆+工具”的完整行动闭环。
Agent四大组件:LLM(推理中枢)+ 规划(任务拆解)+ 记忆(分层存储)+ 工具(调用外部能力)。
RAG定位:Agent记忆模块的核心实现方式,解决知识过时和幻觉问题。
面试关键:不仅要背定义,更要理解对比关系(LLM vs Agent、RAG vs Agent)和工程落地难点。
重点提示:2026年面试官不再满足于“背概念”,高频追问框架选型理由、失败场景处理、成本与效果的权衡——这些才是拉开差距的关键-41。
下篇预告:本文侧重于概念理解和面试基础。下一篇将从Agent的底层原理与工程化落地切入,深入讲解ReAct框架实现细节、RAG架构演进(GraphRAG)、MCP协议标准以及Agent安全护栏设计等进阶内容。欢迎持续关注。