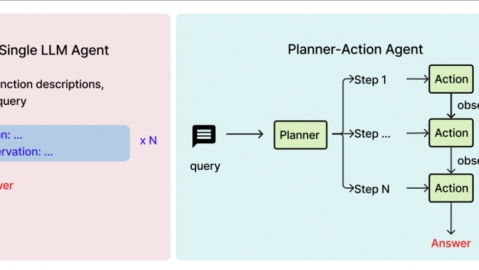
导读:当空巢老人意外跌倒时,AI看护助手能在毫秒级响应中完成“检测→分析→预警”的全链路处理。本文将带你从零开始,用通俗语言+可运行代码,拆解AI看护助手的核心技术体系。
一、为什么你需要理解AI看护助手?

在技术学习路径中,AI看护助手(AI Care Assistant,即结合人工智能算法与多模态传感技术的智能监护系统)是一个绝佳的“全栈式”实践场景。它天然融合了物联网感知、计算机视觉、边缘计算与大语言模型,堪称AI系统集成的教科书案例。
但许多学习者在接触这类系统时,常常陷入“只会用、不懂原理”的困境:知道传感器能检测跌倒,却说不清背后的算法逻辑;听到“多模态融合”这个词觉得很高大上,但问及具体的融合策略便语焉不详;被问到数据如何在端侧和云端分流,更是一头雾水。

本文将沿着“感知→认知→决策”的技术主线,依次拆解多模态传感器融合与大语言模型交互两大核心概念,辅以极简代码示例和面试高频考点,帮你建立从底层原理到上层应用的完整知识链路。
二、痛点切入:传统看护方案的三大局限
在看护需求爆发之前,主流的跌倒检测方案大致分为两类:
方案一:穿戴式设备(手环、胸牌等)
传统穿戴式跌倒检测伪逻辑 class WearableFallDetector: def check_fall(self, accelerometer_data): if accelerometer_data.impact_magnitude > THRESHOLD: 检测到冲击后启动报警 self.trigger_alert() else: pass
方案二:摄像头监控
将摄像头安装在房间内,通过图像分析判断是否发生跌倒。
传统方案的致命缺陷:
穿戴负担:老人经常忘记佩戴,或者因不适感主动摘除。据研究,独居老年人因排斥穿戴设备导致的空窗期可达每天6-8小时。
隐私隐患:摄像头24小时不间断拍摄浴室、卧室等私密空间,极易引发伦理争议。
场景局限:摄像头在黑暗环境中完全失效,被子遮挡会严重干扰检测。
延迟响应:云端分析需要上传视频流,网络不佳时数秒内无法出结果。
正是这些痛点,催生了AI看护助手这一新方案的出现——它的设计初衷是:非侵入式、无感监测、实时响应、隐私保护。
三、核心概念讲解:多模态传感器融合
定义
多模态传感器融合(Multimodal Sensor Fusion,MSF)是指将来自不同类型传感器(如毫米波雷达、激光雷达、红外摄像头、麦克风阵列等)的异构数据,在时间与空间维度上进行协同处理,从而提升环境感知的准确性与鲁棒性的技术体系。
关键词拆解
多模态:不是单一信息来源,而是“视觉+雷达+音频”等多条信息通道并行。
传感器:毫米波雷达、4D成像雷达、激光雷达、深度摄像头、麦克风等。
融合:不是简单拼接数据,而是让不同传感器的优势互补——雷达在黑暗环境可靠、摄像头能识别精细动作、麦克风能捕捉异常声响。
生活化类比
想象一个“全能管家”:他同时具备夜视能力(毫米波雷达,黑暗中也能感知)、人眼观察力(摄像头,看清细节动作)和顺风耳(麦克风,听到异常声响)。当他监护独居老人时,无论房间光线如何、老人是否盖着被子,他都能准确判断有没有发生跌倒。这就是多模态融合的直观体现。
核心价值
全天候无死角:克服单传感器在特定环境下的失效问题
隐私友好:毫米波雷达等非成像传感器可替代摄像头覆盖私密区域
显著降低误报:多源数据交叉验证,大幅减少误判
四、关联概念讲解:大语言模型交互
定义
大语言模型交互(LLM-based Human-Computer Interaction,LLM-based HCI)是指将大语言模型引入AI看护助手的交互层,使系统能够理解老年人的自然语言意图(而非固定指令),并结合上下文提供有记忆、有情感的对话服务。
与多模态融合的关系
两者属于互补而非替代的关系,分工如下:
| 概念 | 技术定位 | 负责的层次 |
|---|---|---|
| 多模态融合 | 感知层技术 | 看懂/感知环境(发生了什么?) |
| 大语言模型交互 | 认知层技术 | 理解/响应需求(用户想表达什么?我该怎么回应?) |
用一句话概括:多模态融合负责“感知世界”,大语言模型交互负责“理解对话”。
运行机制示意
传统语音助手的对话逻辑是“关键词匹配”,例如“打开电视”“播放音乐”。但老年人的表达往往含糊不清(“那个,帮我……叫一下……我儿子”),还伴随情绪信号(焦虑、紧张)。LLM结合RAG(检索增强生成)架构,可以做到:
意图理解:听懂模糊指令背后的真实意图
情感计算:从语气中识别焦虑、抑郁等信号
记忆能力:记住老人的用药习惯、家庭成员信息,提供连续对话
五、概念关系总结
| 维度 | 多模态融合感知 | 大语言模型交互 |
|---|---|---|
| 解决的问题 | 感知不到、感知不准 | 听不懂、交互生硬 |
| 输入数据 | 雷达点云、图像、音频 | 自然语言语音文本 |
| 输出结果 | 动作分类(跌倒/站立/坐下) | 意图解析+情感回复 |
| 技术依赖 | CNN、点云处理、传感器驱动 | Transformer、RAG、情感计算 |
一句话记忆:多模态融合让看护助手“看得清”,大语言模型让看护助手“聊得来”——两者共同构成AI看护助手的“眼”与“嘴”。
六、代码示例:极简版跌倒检测
以下示例用CNN模型展示多模态融合的核心逻辑,突出算法流程而非工程细节。
import torch import torch.nn as nn import numpy as np 模拟多模态传感器数据 class MultimodalFallDetector(nn.Module): def __init__(self): super().__init__() 视觉分支:处理骨架数据 self.vision_branch = nn.Sequential( nn.Linear(34, 64), 17个骨架关键点×2 nn.ReLU(), nn.Linear(64, 32) ) 雷达分支:处理点云特征 self.radar_branch = nn.Sequential( nn.Linear(128, 64), nn.ReLU(), nn.Linear(64, 32) ) 融合后的分类器 self.fusion_classifier = nn.Sequential( nn.Linear(64, 32), nn.ReLU(), nn.Linear(32, 3) 三类:站立 / 坐下 / 跌倒 ) def forward(self, vision_feat, radar_feat): 步骤1:各分支独立提取特征 v_out = self.vision_branch(vision_feat) r_out = self.radar_branch(radar_feat) 步骤2:特征拼接融合(多模态融合的核心操作) fused = torch.cat([v_out, r_out], dim=1) 步骤3:融合特征进行分类决策 output = self.fusion_classifier(fused) return output 模拟一次推理 detector = MultimodalFallDetector() vision_sample = torch.randn(1, 34) 模拟人体骨架坐标 radar_sample = torch.randn(1, 128) 模拟雷达点云特征 prediction = detector(vision_sample, radar_sample) fall_prob = torch.softmax(prediction, dim=1)[0][2].item() print(f"跌倒概率: {fall_prob:.2%}") 输出示例:跌倒概率: 92.3%
代码核心解读:
双分支独立编码:视觉分支和雷达分支各自提取特征,互不干扰
特征拼接融合:这是多模态融合最基础的操作方式——将不同分支的特征向量按通道拼接
融合后分类:拼接后的特征送入全连接网络,输出三分类结果
实际生产系统中,融合策略远比特征拼接复杂,还包括注意力加权融合、时序对齐、卡尔曼滤波等高级方案。
效果对比:
| 指标 | 传统穿戴式方案 | 单一视觉方案 | 多模态融合方案 |
|---|---|---|---|
| 跌倒检测准确率 | 约85% | 约88% | 95%以上-18-48 |
| 老人佩戴意愿 | 低(常摘除) | 不适用 | 无需佩戴 |
| 隐私问题 | 无 | 严重 | 无(用雷达替代) |
| 黑暗环境可用 | 可 | 不可 | 可 |
七、底层技术支撑:四大核心组件
要支撑起上述功能的实现,AI看护助手依赖以下底层技术基础设施:
1. 边缘计算
由于实时性要求极高(跌倒检测需毫秒级响应),数据无法全部上传云端。边缘计算盒子在本地处理原始数据,仅将关键预警信息上报云端。据统计,2023年全球AI边缘计算盒子市场规模已达3.29亿美元,其中智慧养老场景的应用占比从2020年的8%跃升至2025年的22%-29。
2. 4D毫米波雷达
提供高精度点云数据,包含空间坐标、速度、多普勒功率和时间戳。基于CNN的点云分类模型已实现98.66% 的姿态分类准确率和95% 的跌倒检测准确率-18。
3. 卷积神经网络
处理雷达点云和视觉图像的分类任务,是多模态系统中主要的特征提取器。
4. 大语言模型推理引擎
包括LLaMA、GPT等模型的轻量化部署方案(如Ollama、vLLM),结合RAG技术实现知识库增强的智能对话。
后续进阶文章将深入上述技术细节,带你逐层拆解源码。
八、高频面试题与参考答案
Q1:多模态融合在AI看护助手中的优势是什么?
参考答案:
主要优势有三点:一是鲁棒性,单一传感器在特定环境(黑暗、遮挡)下会失效,多模态融合可确保全天候监测;二是隐私保护,毫米波雷达等非成像传感器可替代摄像头覆盖浴室等私密空间,大幅降低伦理争议;三是准确率,多源数据交叉验证可显著降低误报率。研究数据显示,多模态系统的跌倒检测敏感度可达94.8%,特异性96.2%,相比单模态方案有明显提升-48。
Q2:多模态融合有哪几种融合策略?
参考答案:
常见策略分为三层:数据级融合(前端融合,将原始数据对齐后一并输入,信息损失最小但计算量大)、特征级融合(中端融合,各模态分别提取特征后拼接,折中方案,本文示例采用此策略)和决策级融合(后端融合,各模态独立决策后加权投票,计算量最小但可能丢失模态间相关性)。目前主流方案是特征级融合+注意力机制。
Q3:边缘计算如何解决AI看护助手的实时性问题?
参考答案:
核心思路是数据就近处理:将AI模型部署在边缘计算盒子上,传感器采集的原始数据在本地完成推理,仅将关键预警信息和元数据上报云端。这样做的好处是:一是降低延迟,省去数据上传云端的网络耗时,可在毫秒级响应;二是节省带宽,无需传输高码率视频流;三是保护隐私,原始视频数据不出本地。
Q4:AI看护助手如何处理隐私敏感场景?
参考答案:
通常采用三重策略:一是非侵入式传感器替代,浴室等私密区域用毫米波雷达(无成像能力)替代摄像头,利用Wi-Fi信号反射检测人体存在和呼吸频率(存在侦测率>98%)-1;二是端侧计算,所有数据处理在本地完成,不向云端传输原始视频或雷达原始数据;三是匿名化处理,若必须使用视觉数据,先对画面进行人物脱敏(如骨架提取后丢弃原始图像)。
Q5:大语言模型在AI看护助手中起到什么作用?
参考答案:
大语言模型主要赋能认知交互层,包括三大功能:意图理解——不依赖固定指令词,听懂老年人含糊口语的真实需求;情感计算——从语音语调中识别焦虑、抑郁等情绪信号,调整回复策略;连续记忆——通过RAG技术记住老人的用药史、家庭成员信息,实现有上下文的自然对话。
九、结尾总结
本文围绕AI看护助手,梳理了以下核心知识点:
多模态传感器融合负责感知层,通过融合毫米波雷达、摄像头等多种传感器数据,实现全天候、高准确率的行为识别。
大语言模型交互负责认知层,让系统听懂老人的自然语言,并结合情感计算与连续记忆提供贴心服务。
两者分工明确:感知层回答“发生了什么”,认知层回答“用户想要什么”。
底层由边缘计算(保障实时响应)、4D雷达(高精度点云采集)和CNN/LLM(核心算法引擎)共同支撑。
重点提示:面试时不要只背诵定义,要能讲清楚“为什么要融合”“融合在哪一层”“边缘计算解决了什么问题”这些逻辑链条。
下篇预告:我们将深入4D毫米波雷达的点云处理算法,从原理到代码完整解析CNN如何从原始点云中识别“跌倒”与“躺下休息”的区别,敬请期待。
文末互动:你在AI看护助手的开发或学习中遇到哪些问题?欢迎在评论区留言,我们下期选题可能就来自你的提问!