发布时间:2026年4月8日
开篇引入

在AI技术快速迭代的今天,AI助手取名已经从产品经理的“灵感火拼”演变为一个可工程化的技术命题。无论是给智能体(Agent)设定名称,还是为大模型产品打造品牌标识,“如何让AI懂取名”已成为AI应用开发者的必修课。很多学习者面临一个尴尬局面:会用现成的AI命名工具,却搞不懂背后的生成逻辑;知道怎么调接口,却答不出面试官问的“LLM如何生成合规名称”。本文将从零出发,带你系统理解AI命名的技术原理,配合可运行的代码示例,梳理高频面试考点,帮你打通从“会用”到“懂原理”的完整链路。
一、痛点切入:为什么需要AI命名
在AI命名技术出现之前,产品的命名工作主要依赖人工创意或简单的随机组合工具。以给Python包取名为例,开发者需要手动构思、查询PyPI是否被占用、反复尝试——一套流程走下来,光是“想名字”就能耗掉小半天。
以下是一个简单的随机组合命名器:
import random adjectives = ["Swift", "Clever", "Bright", "Nano"] nouns = ["Fox", "Hive", "Spark", "Core"] def manual_name_generator(): return f"{random.choice(adjectives)}{random.choice(nouns)}" print(manual_name_generator()) 输出类似 "SwiftFox"
这种方式的痛点显而易见:
缺乏语义理解:无法理解用户指定的风格、情感或文化含义
可扩展性差:词库固定,生成结果极易重复
无法校验可用性:不知道名称是否已被占用
风格单一:无法根据不同场景(如企业品牌 vs 个人项目)动态调整输出
正是这些局限性,催生了AI驱动的智能命名方案。
二、核心概念讲解:大语言模型(LLM)
大语言模型(Large Language Model,LLM) 是指在大规模文本语料上预训练、能够理解和生成自然语言的深度学习模型。
从技术内核来看,LLM的核心任务是预测下一个token,其底层架构基于Transformer,通过自注意力机制(Self-Attention) 捕捉上下文依赖,再配合位置编码(Positional Encoding) 保留顺序信息-68。
生活化类比:把LLM想象成一个“读过全世界所有书籍的图书管理员”。你问他“能帮我给一个数据分析工具取个名字吗”,他会从海量记忆中检索类似命名模式——比如“DataMind”“InsightHub”——然后根据你提供的偏好,组合出最合适的答案。
在AI命名场景中,LLM的作用正是:理解用户给出的描述(如“科技感”“双音节”“英文名”),从训练数据中学到的命名规律出发,生成符合要求的候选名称。
三、关联概念讲解:Agent(智能体)
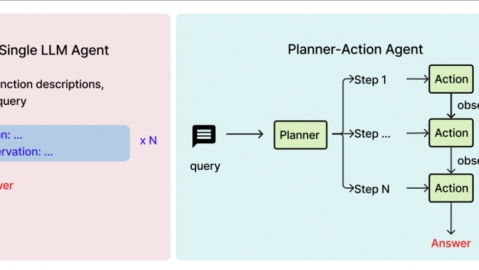
Agent(智能体) 是指以LLM为核心控制器、具备感知环境、制定计划、调用工具并执行行动能力的AI系统。
与普通LLM“只回答问题”不同,Agent可以主动推理和行动。每个Agent遵循一个结构化循环:输入处理 → 推理规划 → 工具选择 → 工具执行 → 结果合成-4。
概念A(LLM)与概念B(Agent)的关系:LLM是“大脑”,Agent是“身体”。LLM负责思考“叫什么名字好”,Agent负责思考后去调用GitHub API查重、查询域名是否可用、甚至把结果保存到数据库。
在实际的AI命名系统中,两者往往协同工作:LLM负责生成创意名称,Agent负责执行后续的可用性校验和自动化流程。
四、概念关系与区别总结
| 维度 | LLM | Agent |
|---|---|---|
| 核心能力 | 文本理解与生成 | 规划、调用工具、执行动作 |
| 输入输出 | 文本→文本 | 文本→可执行结果 |
| 典型工作方式 | 被动响应Prompt | 主动循环推理+行动 |
| 在命名系统中的作用 | 生成候选名称 | 执行查重、域名校验等后续步骤 |
一句话记忆:LLM是“想名字的大脑”,Agent是“动手查重执行的手”。
五、代码/流程示例演示
下面演示一个简化的AI命名代理核心流程,模拟LLM根据用户描述生成名称建议:
import openai openai.api_key = "YOUR_API_KEY" def generate_names_with_llm(description: str, count: int = 5): """ 使用LLM根据描述生成候选名称 description: 名称描述,如 "一个用于数据分析的开源工具" """ prompt = f""" 根据以下描述,生成{count}个创意名称,每个名称占一行: 描述:{description} 要求:名称简洁、有辨识度、与描述主题相关。 """ response = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=[ {"role": "system", "content": "你是一个专业的AI命名助手。"}, {"role": "user", "content": prompt} ], max_tokens=100 ) names = [name.strip() for name in response.choices[0].message.content.split("\n") if name.strip()] return names 示例调用 description = "一个帮助开发者管理代码片段的AI工具" names = generate_names_with_llm(description) print("生成的名称:", names) 预期输出类似:['CodeSnap', 'SnippetAI', 'DevRecall', 'CodeVault', 'FragmentFlow']
关键步骤标注:
System Prompt:设定模型角色,限定输出范围
User Prompt:描述需求 + 明确输出格式要求
解析响应:按分隔符提取结果,处理边缘情况
如果要增加名称长度和字符格式约束,可以在生成后进行过滤:
import re def filter_names(names, max_len=20, pattern=r"^[A-Za-z0-9]+$"): valid = [] for name in names: if len(name) <= max_len and re.match(pattern, name): valid.append(name) return valid
对比新旧方式的改进效果:
旧方式(随机组合):只能产出
"SwiftFox"这种机械拼接,无法理解“数据分析工具”的语义新方式(LLM驱动):能产出
"DataMind""InsightCore"等带有语义关联的名称-67
六、底层原理/技术支撑
AI命名的背后,依赖几个关键的技术基础:
① Transformer与自注意力机制
Transformer的自注意力机制通过计算Q(查询)、K(键)、V(值)的加权和,让模型能够捕捉文本中的远距离依赖关系,理解“科技感”这种抽象描述应该如何映射到具体的命名词汇-68。
② Embedding向量化
Embedding将文本的语义信息映射到向量空间,使得“数据分析”和“洞察挖掘”这类语义相近的词汇在向量空间中彼此接近。这支撑了RAG(检索增强生成)在命名场景的应用:可以从已有的成功命名案例库中检索最相关的示例,引导LLM生成更高质量的名称-68。
③ Few-shot Prompting
在Prompt中提供少量优质示例,模型就能自动分析示例背景与结果之间的推导规律,进而生成符合预期的名称。这种“示例驱动”的方式,比零样本生成效果显著提升-8。
对于希望深入了解的读者,可以进一步学习微调框架(如ms-swift),它整合了超过600个纯文本大模型,支持LoRA等参数高效微调策略,仅需约1GB额外显存即可完成7B级别模型的适配-7。
七、高频面试题与参考答案
Q1:LLM如何用于生成有约束的名称(如长度限制、字符规则)?
参考答案:首先生成候选名称列表,然后通过后处理过滤。具体做法是:用LLM生成一批候选名称,再用正则表达式校验长度和字符集,筛选出符合约束的候选。实际工程中,可以分两步——先让LLM在Prompt中遵循约束,降低违规率;再用代码做二次过滤兜底。-67
Q2:什么是Few-shot提示?在命名场景中如何使用?
参考答案:Few-shot提示是在Prompt中提供少量“问题→答案”示例,引导模型学习输出规律。在命名场景中,先给模型2-3个“描述→好名字”的示例,模型会从中提取命名风格和推导思路,然后生成符合相同模式的名称。相比零样本,Few-shot能大幅提升输出质量。-68
Q3:设计一个AI命名系统时,如何保证名称的唯一性?
参考答案:采用“生成+校验”闭环。LLM负责生成候选名称,Agent或独立服务层负责校验:查询名称库(如PyPI、GitHub API)是否被占用。使用集合(Set)去重是基础手段,更完善的方案是引入向量检索,通过语义相似度避免生成过于相似的名称。-67
Q4:Transformer的自注意力机制在命名生成中起什么作用?
参考答案:自注意力机制让模型能够识别输入描述中哪些关键词更重要。比如用户说“一个带有诗意和科技感的名字”,模型会同时关注“诗意”和“科技感”两个维度,在生成的名称中体现两者的融合,而不是偏废其一。-68
Q5:简单随机组合和LLM生成的主要区别是什么?
参考答案:随机组合只能产出词库内的机械拼接,不具备语义理解能力。LLM生成能理解用户意图,从训练语料中提取命名规律,生成语义相关、风格可控的名称。评测数据显示,基于LLM的方法相比传统方法,精确匹配率提升52%,编辑距离降低32%。-11
八、结尾总结
本文围绕 AI助手取名 这一主题,梳理了四大核心知识点:
| 知识点 | 要点总结 |
|---|---|
| LLM | 大语言模型,Transformer架构,核心是预测下一个token |
| Agent | 智能体,LLM+工具调用,实现“思考+行动”闭环 |
| LLM vs Agent | 大脑 vs 身体,协同完成命名生成与校验 |
| 工程要点 | Few-shot提升质量,后处理保证合规,向量检索支持查重 |
学习建议:先跑通基础的LLM API调用示例,理解Prompt如何影响输出;再逐步引入后处理过滤和Agent工具调用,打造一个完整的命名助手。
进阶方向:接下来可以深入探讨微调(Fine-tuning)与提示工程(Prompt Engineering)的取舍、多Agent协作命名框架(如NAMeGEn)的设计思想,以及RAG在命名场景中的应用实践-12。欢迎持续关注本系列更新。
本文参考资料:ACM Proceedings on Software Engineering(2025)、arXiv NAMeGEn框架论文(2025)、Credmark AI面试题库(2025)、阿里云开发者社区AI面试问题清单(2025)、腾讯云智能体开发文档(2025)等。